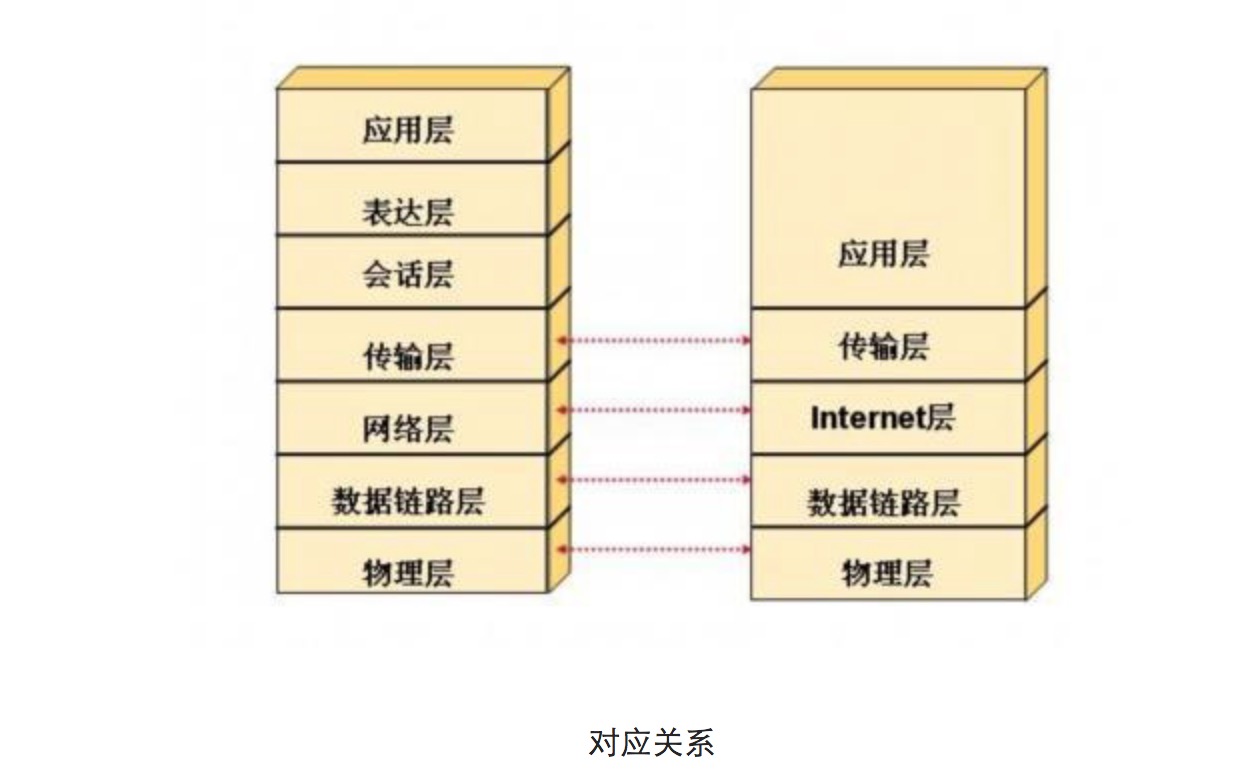
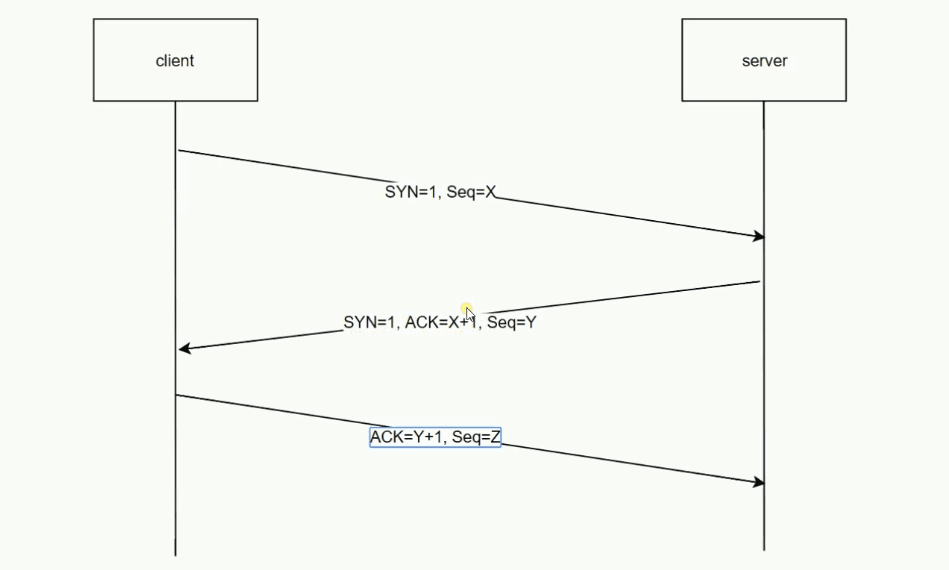
1.http长连接
短连接:在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。
长连接:HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
实验代码:
前端:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
img {
width: 400px;
height: 200px;
}
</style>
</head>
<body>
<img src="http://localhost:3000/1.jpg"/>
</body>
</html>
后端代码
1 | let koa = require('koa'); |
自己在app.js同级建一个名字为imgs的目录丢进去一张图片,修改一下代码里的图片名称
运行前端代码1
$ http-server # 自行用npm安装,在这里代理前端的代码
运行后端代码1
$ node app.js
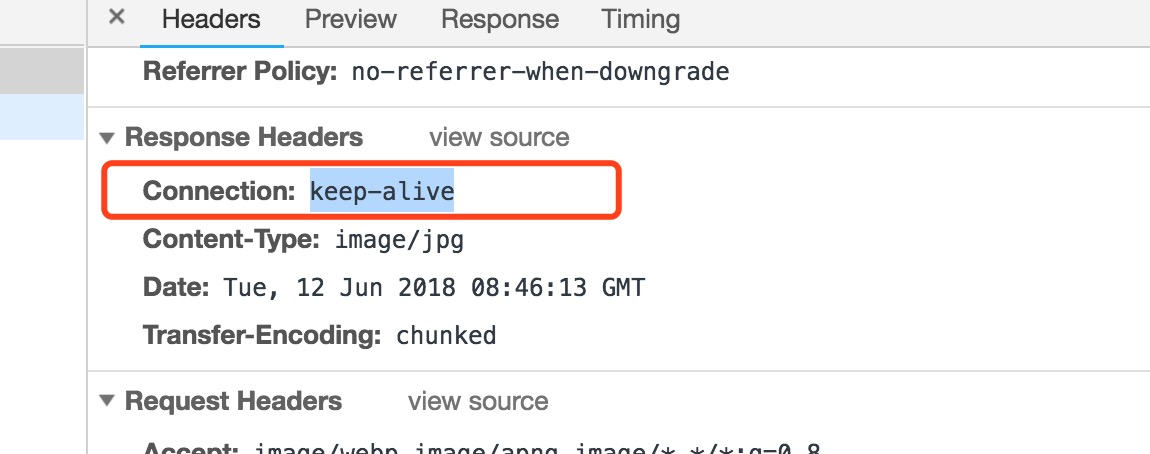
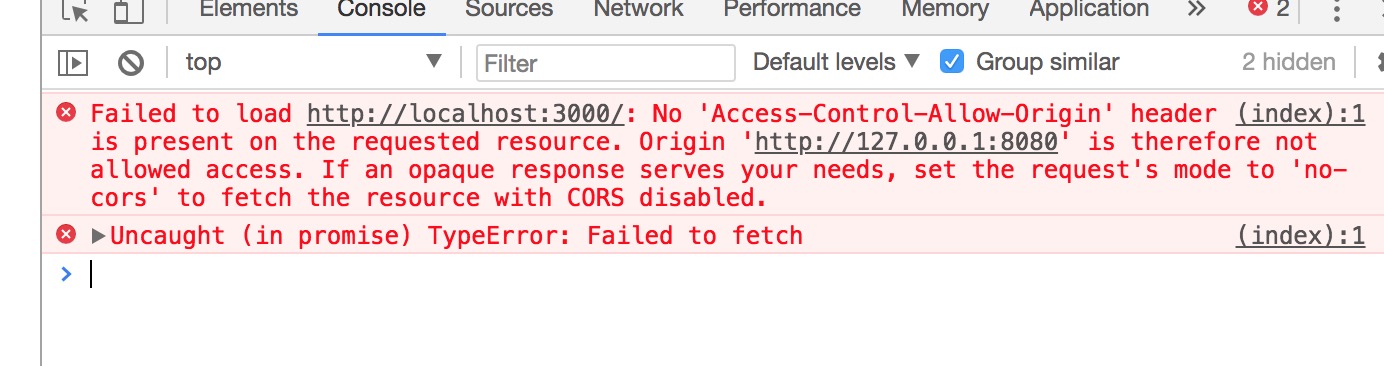
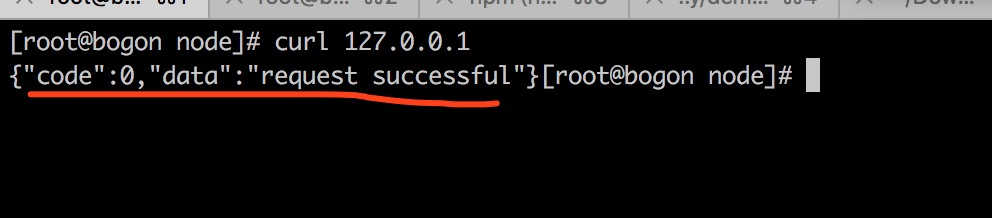
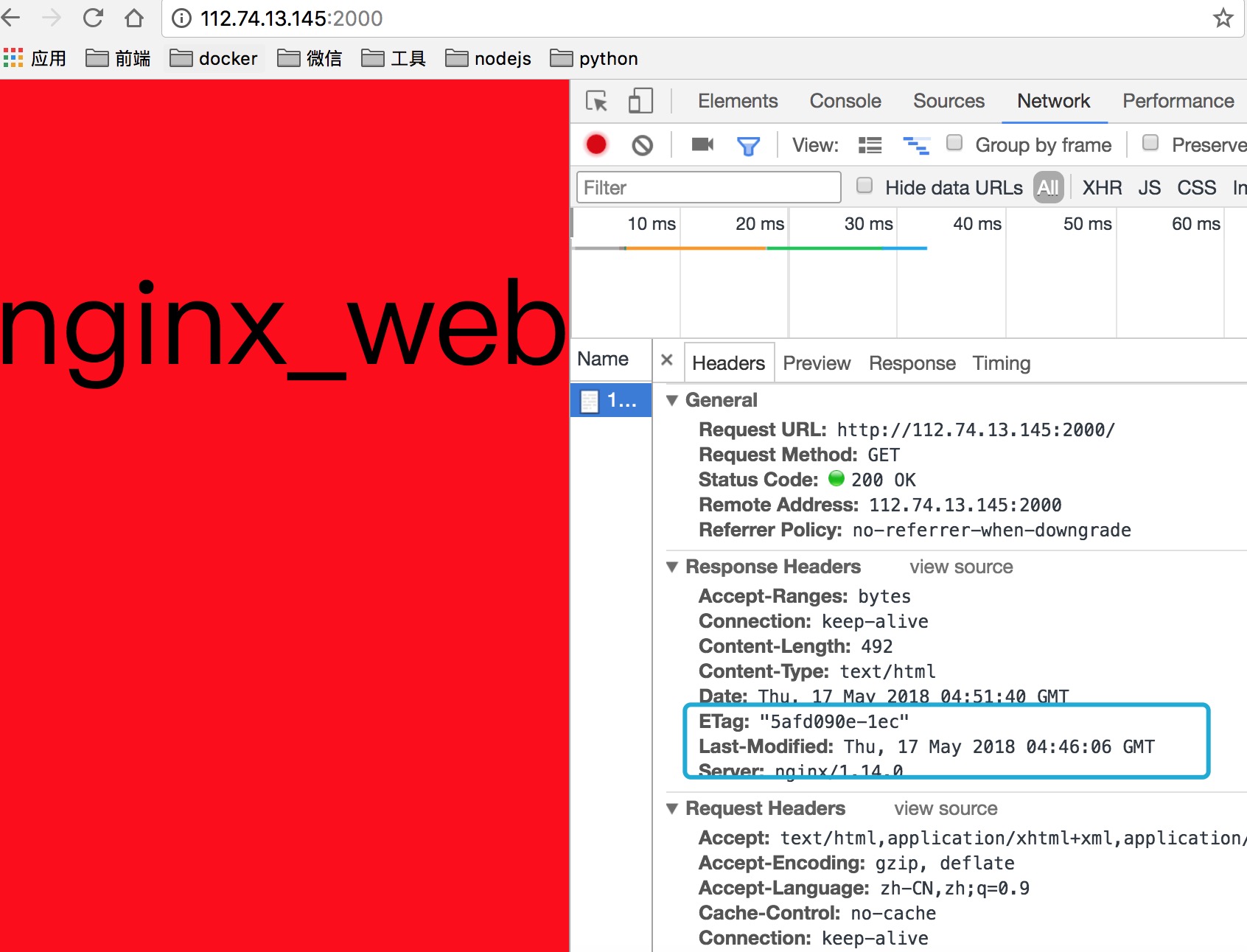
可以看到response是有一个Connection:keep-alive,表示当前链接,server响应完前端的请求不会立即关闭。
如果多加一些请求,实验环节,多请求一些图片:
前端代码修改为
1 | <img src="http://localhost:3000/1.jpg"/> |
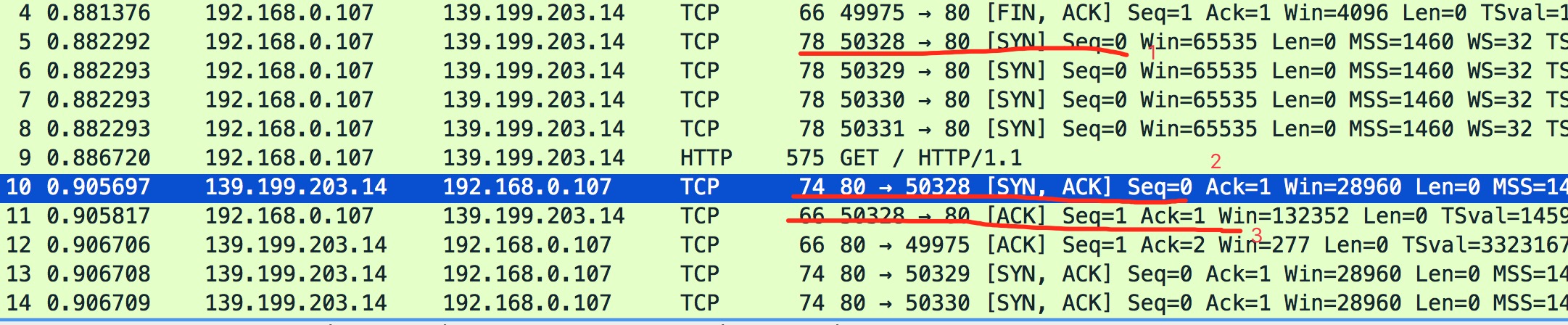
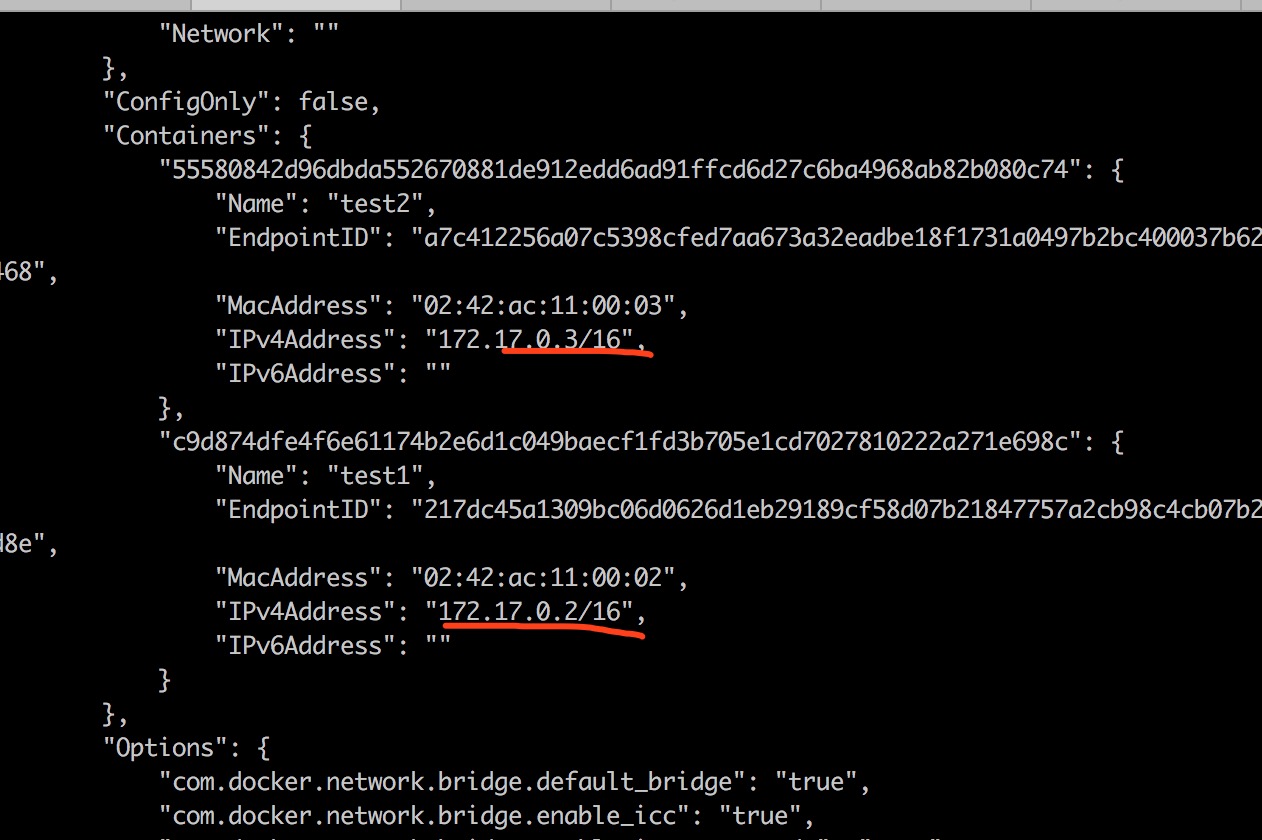
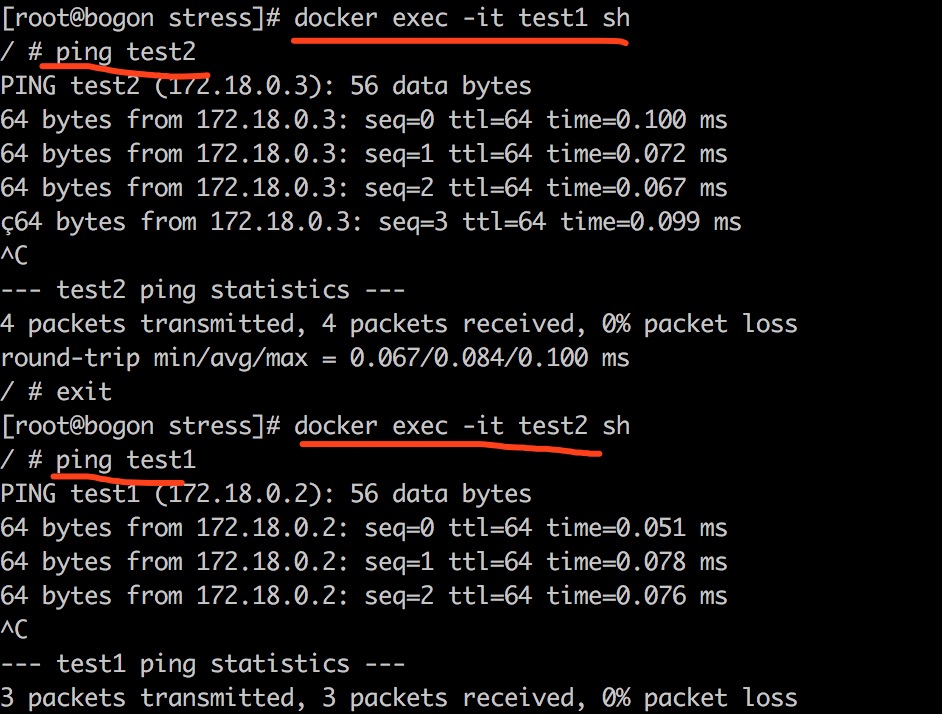
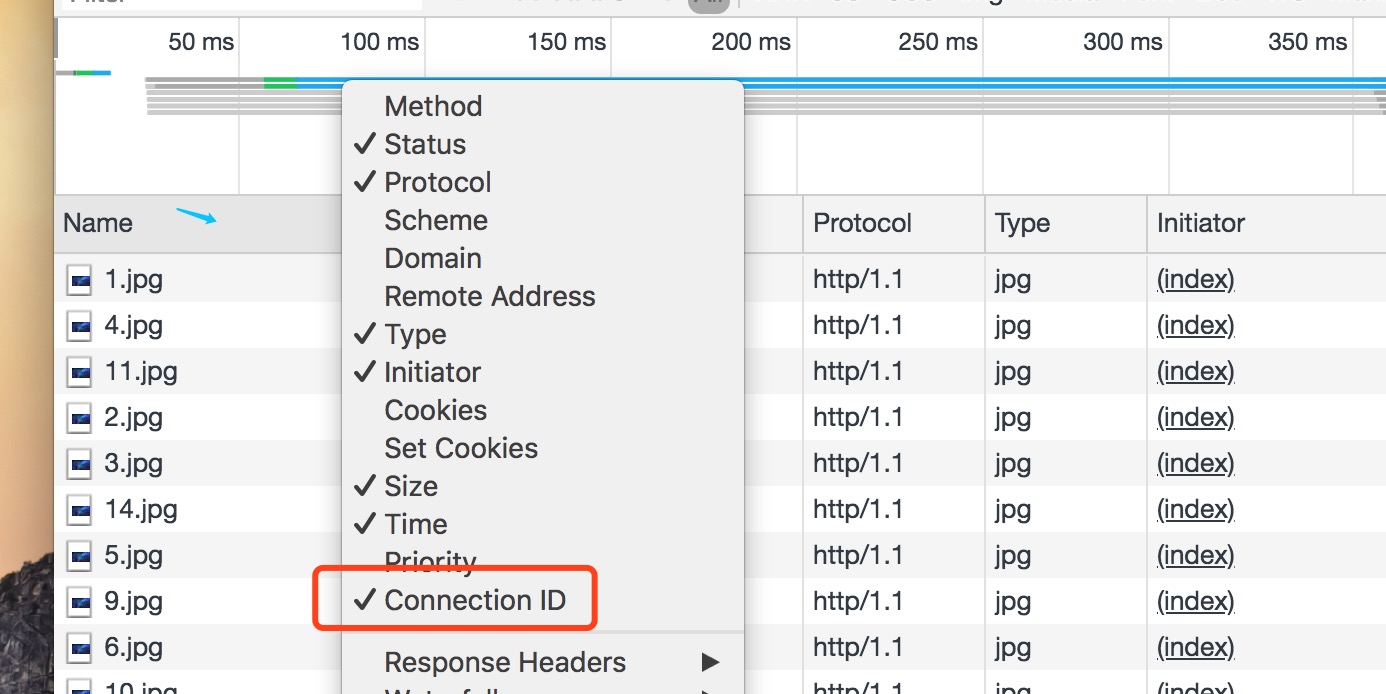
通过选择空白出右键勾上Connection ID选项,可以方便的查看请求使用的tcp链接:
然后访问浏览器查看network:
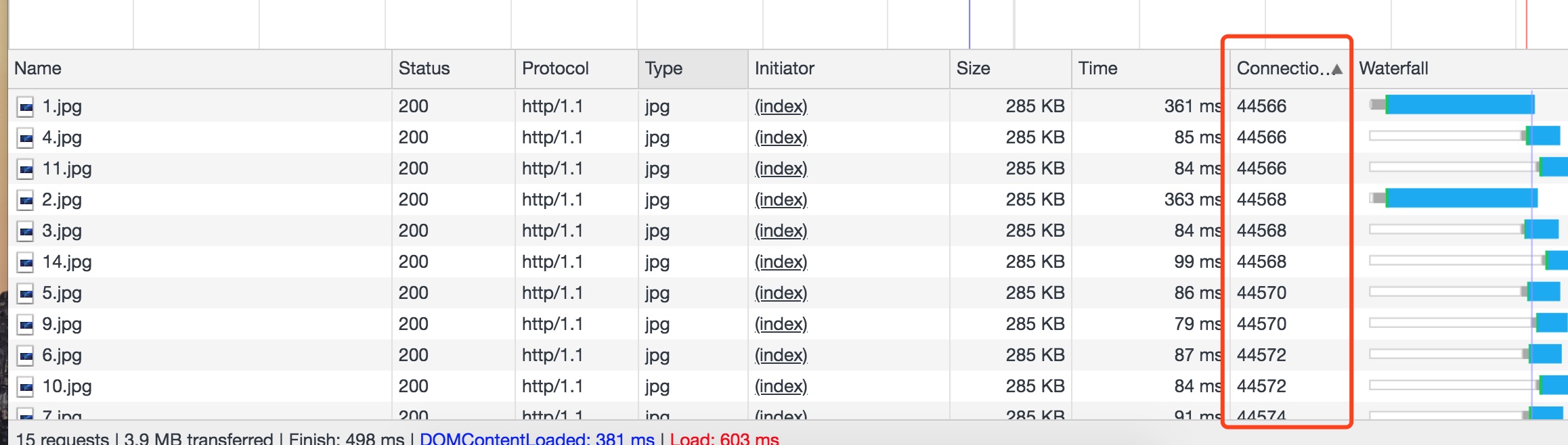
通过浏览器的network可以看到不同的请求会重复使用一个tcp链接的,也就是说明connection没有立即关闭。
2.cookie
实验代码:
前端:1
2
3
4
5
6
7
8<script>
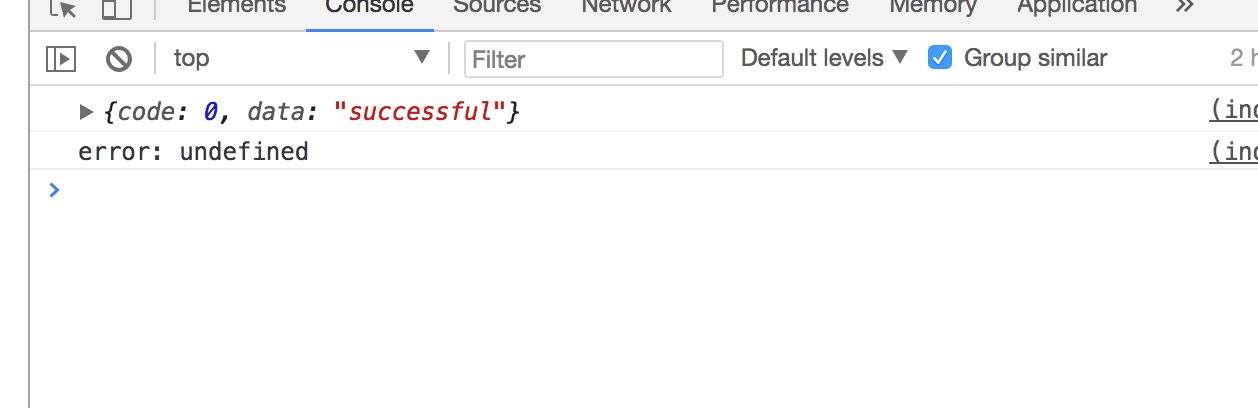
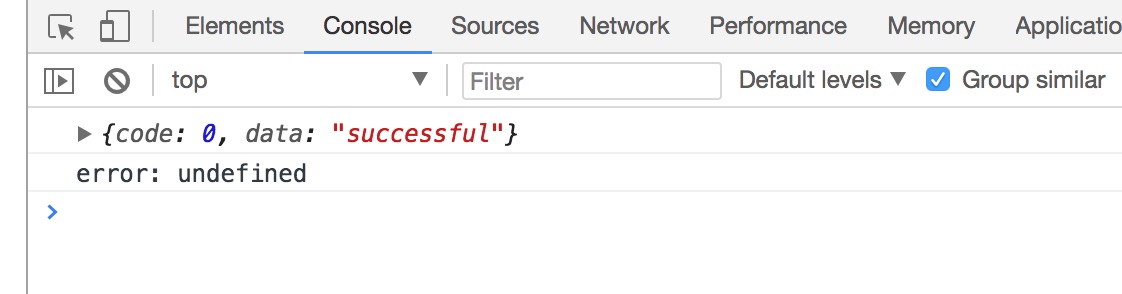
fetch('http://localhost:3000/1.js')
.then((res) => {
return res.text();
}).then(data => {
console.log(data);
})
</script>
后端:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17let koa = require('koa');
let app =new koa();
app.keys = ['im a newer secret', 'i like turtle'];
app.use(async (ctx, next) => {
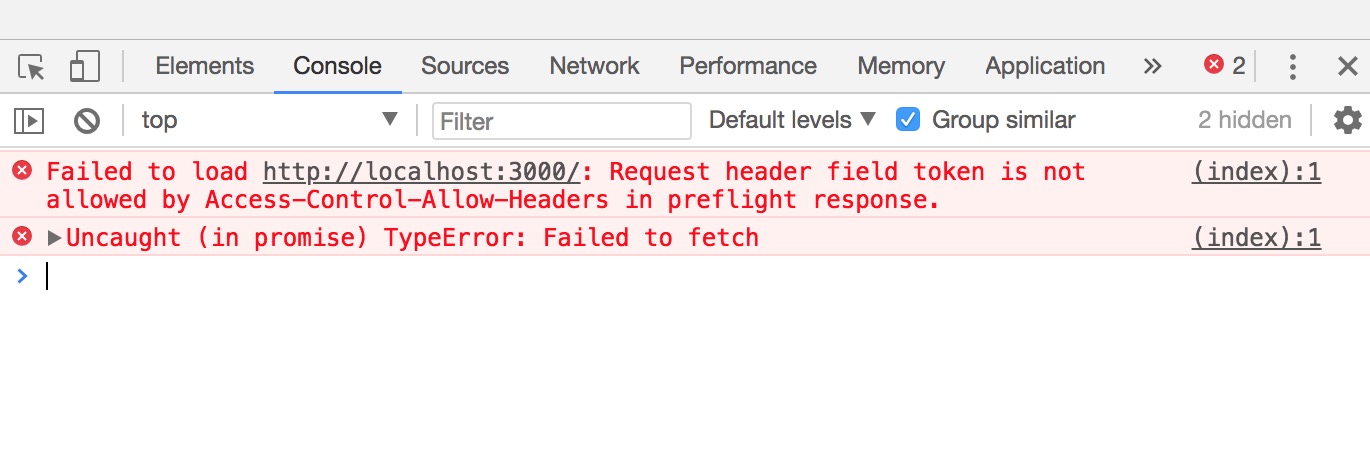
ctx.set("Access-Control-Allow-Origin","*");
if (ctx.request.url === '/1.js') {
ctx.cookies.set('name', 'tobi', {
sign: true,
maxAge: 10,
httpOnly:false
});
ctx.body = `console.log("hello everyone")`;
}
});
app.listen(3000, () => {
console.log(`listen 3000 ...`);
})
cookie 的配置选项:
| 参数 | value |
|---|---|
| max-age | 多少秒后过期 |
| expires | 过期的时间点 |
| secure | 只允许https传输 |
| domain | 设置的域名,设置主域名,子域名也可以使用 |
| httpOnly | 前端js是否允许操作js |
| overwrite | 是否允许重写 |
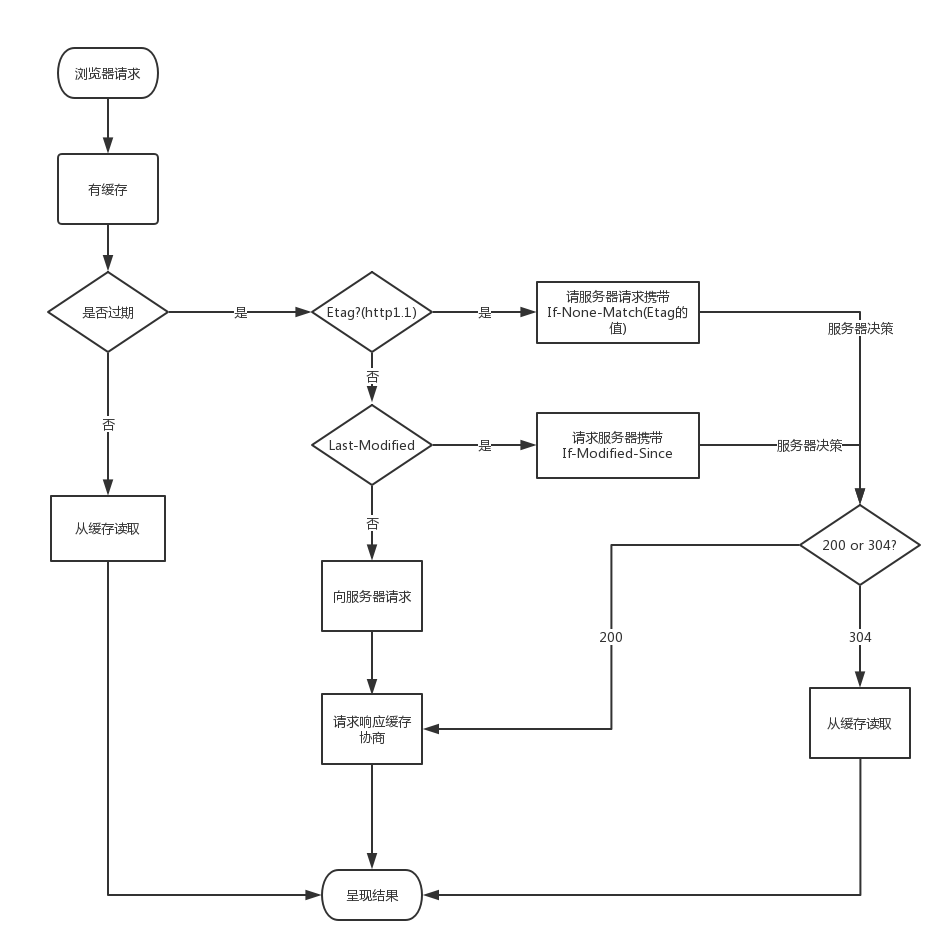
如果max-age 和expires 都没有设置会cookie会在会话关闭消失。
可以通过设置不同的参数给浏览器。
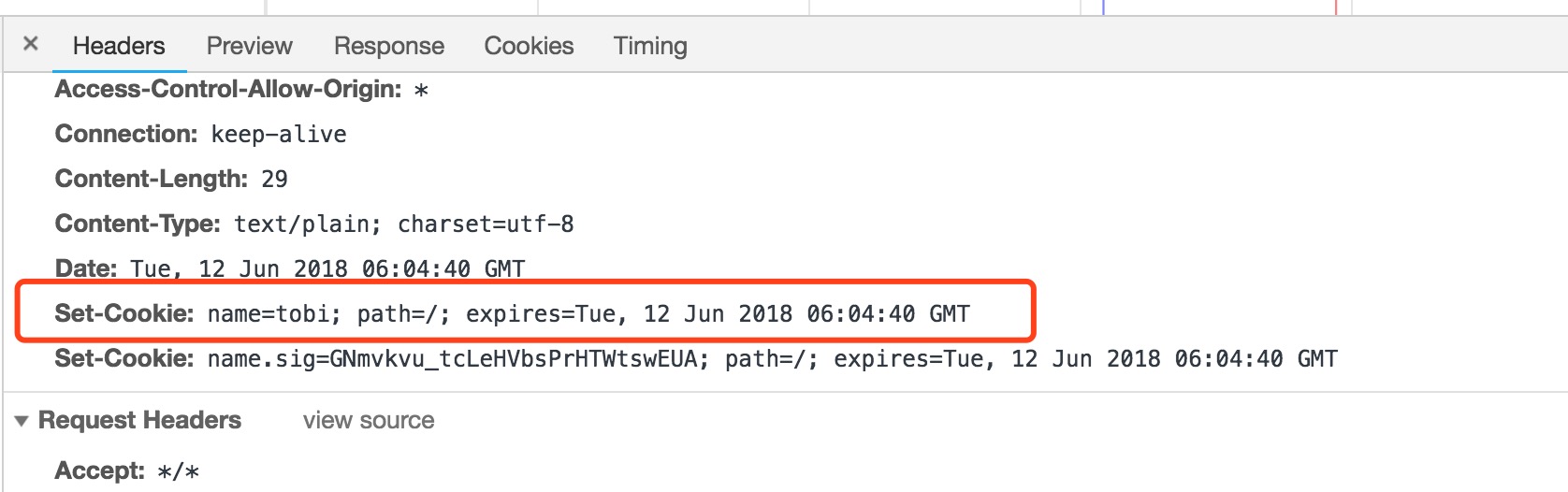
3.数据协商
数据协商:浏览器 和服务器通信的时候,浏览器会告诉服务器我需要什么格式的数据,我希望是接收什么语言,我能解压哪些压缩格式,压缩的代码。
举个例子:
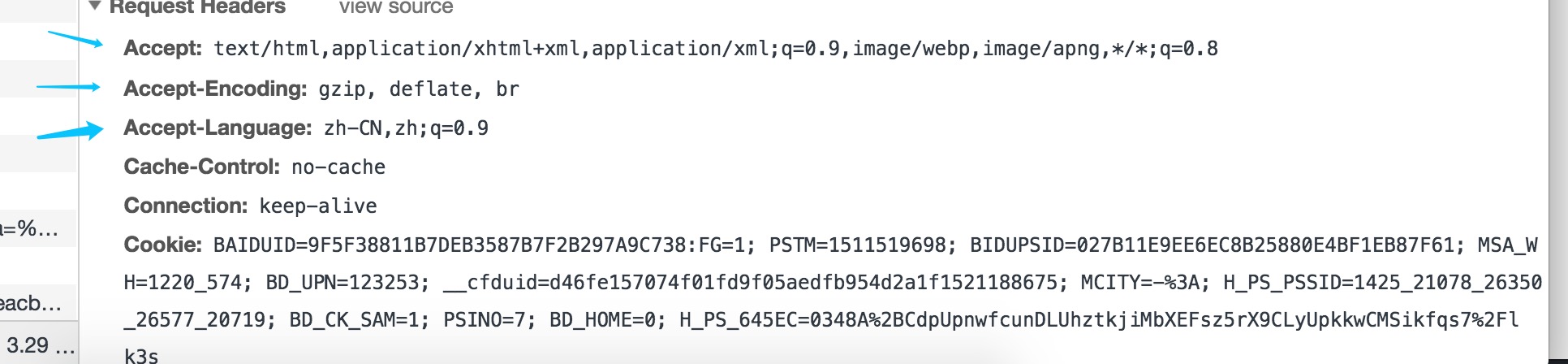
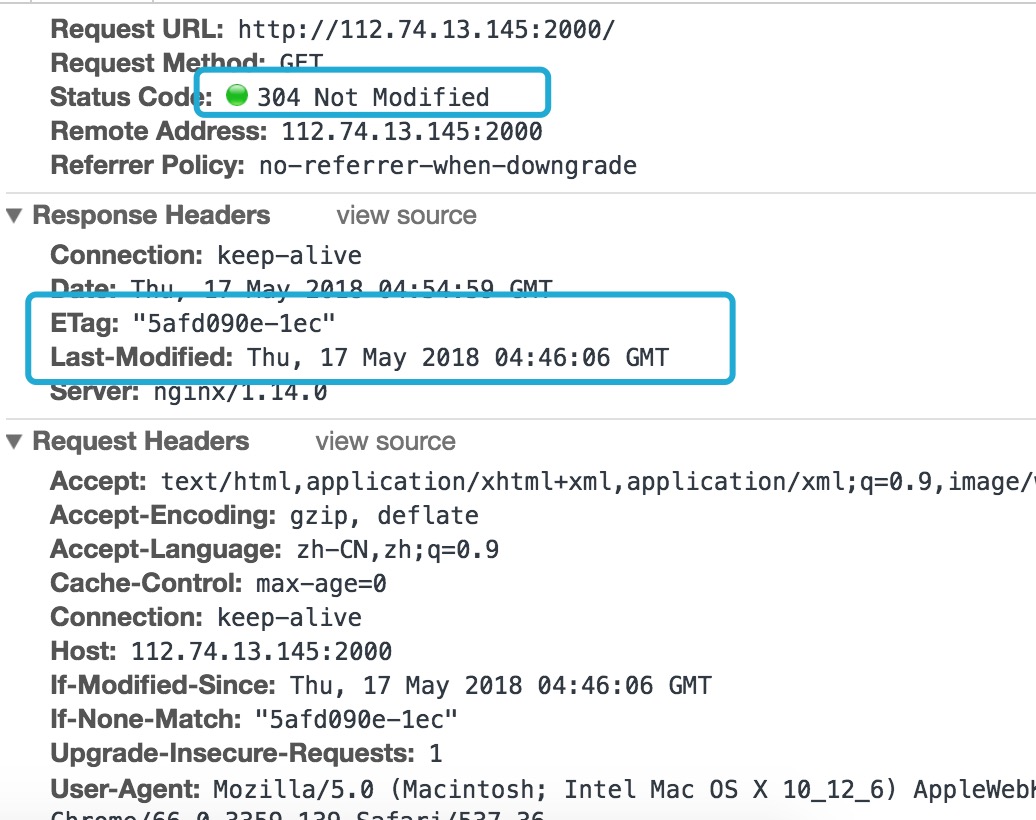
上图中的Accept、Accept-Encoding、Accept-Language 分别告诉浏览器希望接收什么样的消息,什么压缩算法、什么语言。
q=0.9 表示前面的格式代表的权重,权重越大更希望服务器返回权重大的,如果服务器没有,一次往下排。
这些是浏览器根据http协议的规范带上去的,至于服务器端会不会也完全遵守http协议?确不一定。
再看一张服务器返回(response)的图:
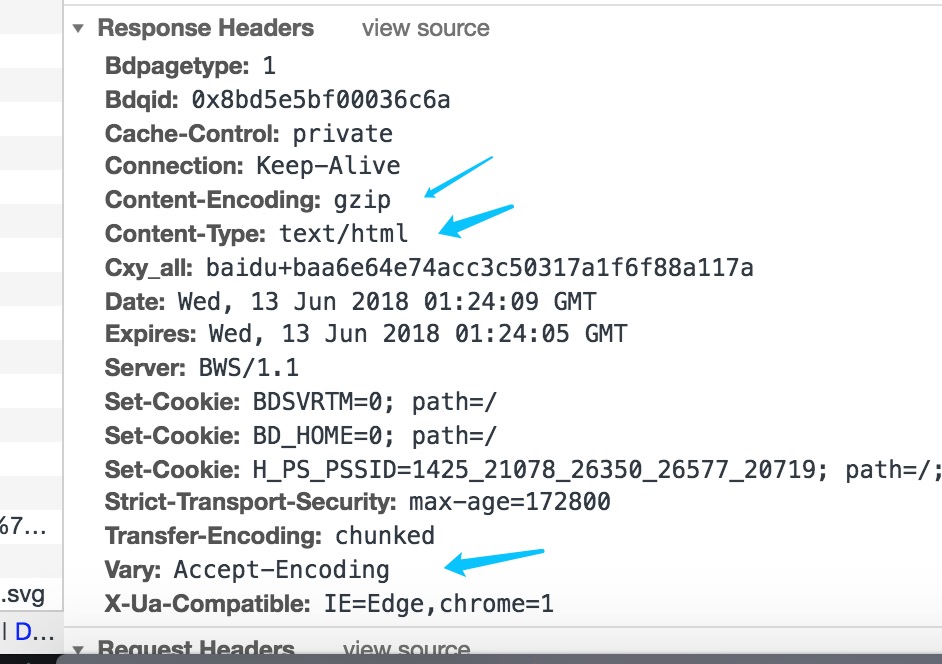
1
2
3
4
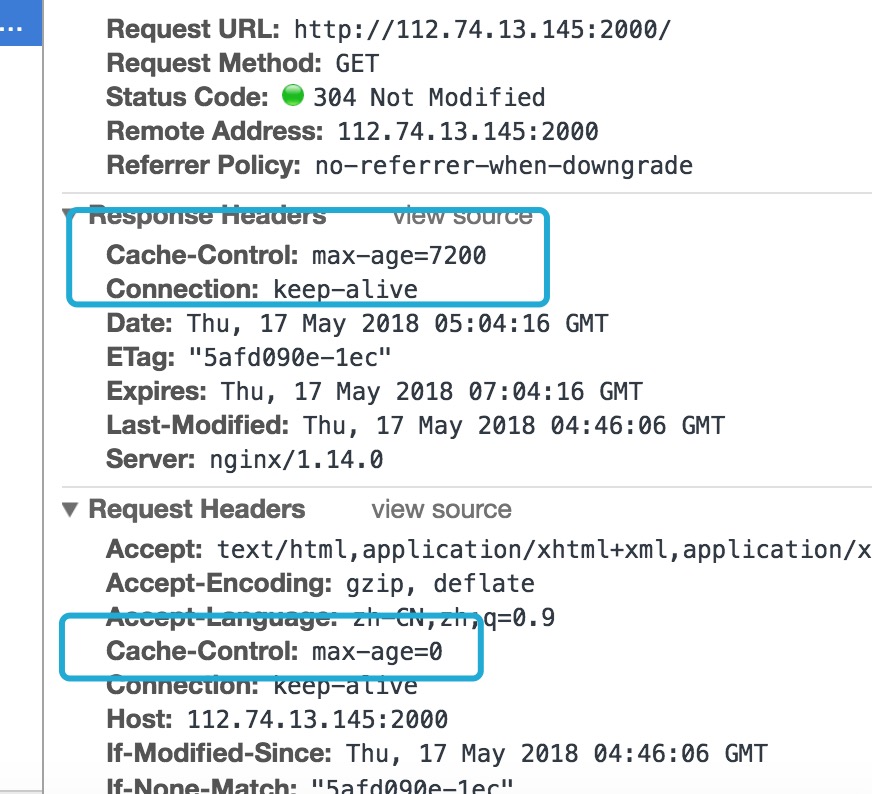
5Cache-Control: private #代理服务器不要缓存
Connection: Keep-Alive # 长连接
Content-Type: text/html# 服务器返回的消息的格式,和request里的Accept 对应。
Content-Encoding: gzip # 是服务器返回的压缩方式。
Vary: Accept-Encoding # 如果 url 和Accept-Encoding 相同才使用代理服务器的缓存,否则不用代理服务器的缓存 (一个请求从浏览器到服务器中间可能经过很多的代理服务器,如果服务器设置了s-max-age,会被代理服务器缓存的,相同的请求可能得到的数据来自代理服务器比如nginx)